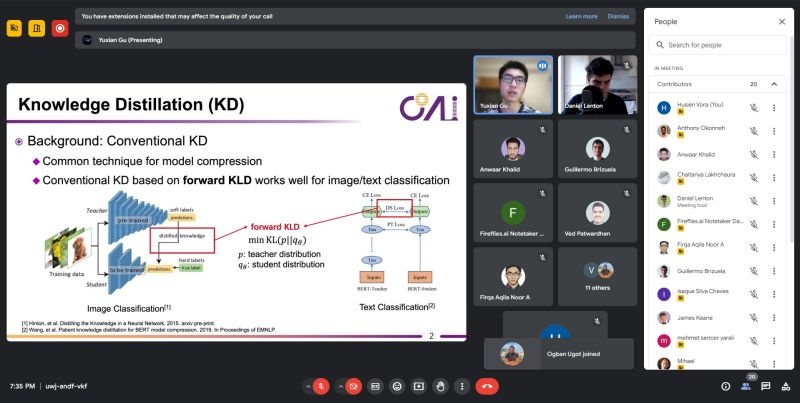
Exploring Knowledge distillation, read the paper MiniLLM: Knowledge Distillation of Large Language Models and got to interact with and listen to one of the authors Yuxian Gu.
"In this work, they replace the forward Kullback-Leibler divergence (KLD) objective in the standard KD approaches with reverse KLD. This prevents the student model from overestimating low-probability regions of the teacher distribution, and the resultant models (MiniLLMs) generate more precise responses with higher overall quality compared to KD baselines
- LinkedIn postLinkedIn post