Exciting work by Mostafa Elhoushi and Akshat Shrivastava from Meta, who co-authored the paper "LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding" .
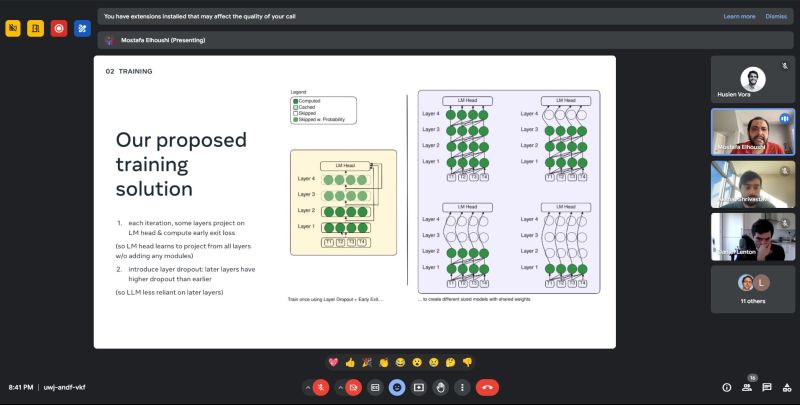
In their work, a single model is used to leverage dynamic compute during generation to enable low-latency high quality predictions within a single model by using the earlier layers to generate tokens and verify with the remaining ones.
Their algorithm is capable of taking advantage of self-speculation and producing high quality outputs at a lower latency while using a single model and KV cache.
- LinkedIn postLinkedIn post